|
1. Who created these corpora?
The underlying
corpus
architecture and web interface were created by
Mark Davies, (retired) Professor of
Linguistics. In most cases, he also designed, collected, edited,
and annotated the corpora as well. In the case of the BNC, Strathy,
EEBO, and Hansard corpora, I received the texts from others, and "just"
created the architecture and interface. So although I use the
terms "we" and "us" on this and other pages, most activities related to the
development of most of these corpora were actually carried out by just one person.
2. Who else
contributed?
3. What is the advantage of these
corpora over other ones that are available?
For some languages and time periods,
these are really the only corpora available. For example, in spite of
earlier corpora like the
American
National Corpus and the
Bank of English, our Corpus of
Contemporary American English is the only large, balanced corpus of
contemporary
American English. In spite of the
Brown family of corpora and the
ARCHER corpus, the Corpus of
Historical American English is the only large and balanced corpus of
historical American English. And while the
ICE
corpora are useful for looking at dialectal variation in English,
the
GloWbE corpus is about 100 times as large (and somewhat more
diverse). Beyond the
"textual" corpora, however, the
corpus architecture and interface that
we have developed allows for speed,
size, annotation, and a range of
queries that we believe is unmatched with other architectures, and which
makes it useful for corpora such as the
British National Corpus, which
does have other interfaces. We believe that the corpora also provide
more than any other corpora in terms of
word sketches, collocates
and related topics, the
ability to analyze entire texts and
the ability to quickly and easily create
Virtual Corpora. Also, the
corpora are free -- a nice feature.
4. What software is used to index,
search, and retrieve data from these corpora?
We have created our own
corpus
architecture, using Microsoft
SQL Server as the
backbone of the relational database approach.
Our proprietary
architecture allows for size, speed,
and very good scalability that
we don't believe are available with any other architecture. Even
complex queries of the more than one billion word COCA corpus or the 475 million word COHA corpus typically only
take two or three seconds (and not much more for the 14 billion word
iWeb
corpus). In addition, because of the relational database
design, we can keep adding on more annotation "modules" with little or
no performance hit. Finally, the relational database design allows for a
range of queries that we
believe is unmatched by any other architecture for large corpora.
5. How many people use the corpora?
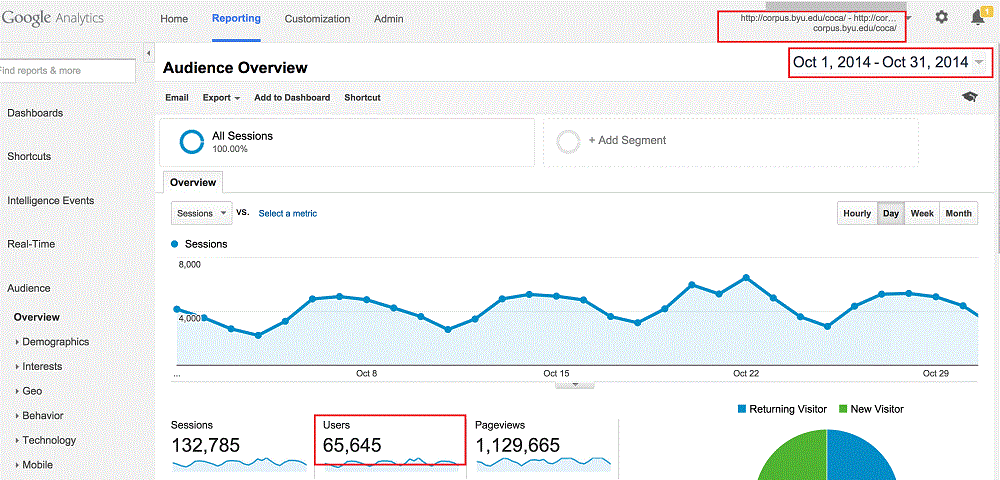
As measured by
Google Analytics, as of
March 2022 the corpora are used by more than 75,000 registered users
each month. The most widely-used corpus is the
Corpus of Contemporary American
English -- with more than 65,000
unique users each month. And people
don't just come in, look for one word, and move on -- average time at
the site each visit is between 10-15 minutes. (More
information...)
6. What do they use the corpora for?
For lots of things. Linguists use the
corpora to analyze variation and change in the different languages. Some
are materials developers, who use the data to create
teaching materials.
A high number of users are language teachers and learners, who use the
corpus data to model native speaker performance and intuition.
Translators use the corpora to get precise data on the target languages.
Other people in the humanities and social sciences look at changes in
culture and society (especially with
COHA and
Hansard). Some businesses purchase data from the
corpora to use in natural language processing projects. And lots of
people are just curious about language, and (believe it or not) just use
the corpora for fun, to see what's going on with the languages
currently. To get a better idea of what people are doing with the
corpora, check out (or search through) the entries from the
Researchers page.
7. What about copyright?
While our corpora contain
some copyrighted material, there is no problem in terms of US copyright
law (or
US Fair Use Law), because users are limited to accessing very limited "Keyword in Context" (KWIC)
displays of the text. It's kind of like the "snippet defense" used by Google. They
retrieve and index billions of words of copyright material, but they
only allow end users to access "snippets" of this data from their
servers. Click here for an
extended discussion of US Fair Use Law and how it applies to our
texts.
8. Can I get access to the full text
of these corpora?
Downloadable, full-text data
is now available for the following corpora: iWeb, COCA, COHA, GloWbE, NOW,
Coronavirus, Wikipedia, SOAP, the TV corpus, the Movie corpus (and for
other languages, and the Corpus del Español and the Corpus do
Português).
9. Is there
API access to the corpora?
No, there isn't. There are two main
reasons for this. First, we don't have copyright access
to the texts in the corpora, and so we can only provide limited access to the
corpora, via the corpus interface. Second, we're already pretty "maxed out" in
terms of the one corpus server, and API access would probably lead to quite a
bit more queries, which we can't handle right now. Although we don't allow API
access, some people have programmed browsers (via Selenium or Python or whatever) to allow for semi-automated queries. (Note,
however, that we
don't provide tech support for this).
10.
My access limits (for "non-researcher") are too low. Can I increase
them?
"Non-researchers"
(Level 1) have 50 queries
a day, or about 1,500 queries per month. For most people, this is way more than
enough. But if you really do need more than
1,500 queries per month, then you might want to upgrade to a premium account, in which case you will have 200 queries a day.
11.
My organization doesn't list my name on a web-page. Can I still register
to use the corpora?
You do not need to register as a
"researcher" to use the corpora. Even the lowest level, default "non-researcher"
status gives you 50 queries
a day, or about 1,500 queries per month. For most people, this is way more than
enough. The only downside is that you won't be included on the
list of researchers, but that's not a huge deal.
On the other hand, if you really do need more than
1,500 queries per month, then you might want to upgrade to a premium account, in which case you will have 200 queries a day (6,000 per
month).
12. I want more data than what's
available via the standard interface. What can I do?
Users can purchase offline data -- such
as full text copies of
the texts, frequency lists,
collocates lists,
n-grams lists (e.g. all two or three word strings of
words).
Click here for much more detailed
information on this data, as well as downloadable samples.
13. Can my
class have additional access to a corpus on a given day?
There is a limit of 250 queries per
24 hours for a "group", where a group is typically a class of students or a
department at a university. If you need more queries than this, you'd want an
academic / site license..
14. I don't
want to see the messages that appear every 10-15 searches as I use the
corpora.
If you have a
premium account, you won't see these messages anymore (during the year in
which your premium account is valid,
if it is for a full year: $34.95).
If you just want a basic account and are
really bothered by the messages, you might want to consider other web-based
corpora -- like those from Lancaster
University (including BNCweb),
CorpusEye, or the many
excellent corpora from Sketch Engine.
(Please be aware, though, that the subscription fee for the Sketch Engine
corpora is
somewhat
more expensive than the cost of a premium account for the corpora -- about
$75 for Sketch Engine, compared to about $35 for English-Corpora.org)
15. How do I cite the corpora in my
published articles? Can I use screenshots from the corpora in my
publication / presentation?
Please use the following information when
you cite the corpus in academic publications or conference papers.
In the first reference to the corpus in your paper, please use the
full name. For example, for COCA: "the Corpus of Contemporary American English"
with the appropriate citation to the references section of the paper, e.g.
(Davies 2008-). After that
reference, feel free to use something shorter, like "COCA" (for example: "...and
as seen in COCA, there are..."). Also, please
do not refer to the
corpus in the body of your paper as "Davies' COCA corpus", "a
corpus created by Mark Davies", etc. The bibliographic entry
itself is enough to indicate who created the corpus. Finally,
please do not refer to any of these corpora as being part of the "BYU
Corpora". Thanks.
You are also welcome to use screenshots from the
corpora in your publication or presentation. There is no need to contact us for
permission. Just provide this URL to your publisher, if they request it.
|
COCA |
Davies, Mark. (2008-) The Corpus of
Contemporary American English (COCA). Available online at https://www.english-corpora.org/coca/. |
|
(Frequency data) |
Davies, Mark. (2008-) Word frequency data from The Corpus of
Contemporary American English (COCA). Data available online at https://www.wordfrequency.info. |
|
(N-grams data) |
Davies, Mark. (2008-) N-grams data from The Corpus of
Contemporary American English (COCA). Data available online at https://www.ngrams.info. |
|
(Collocates data) |
Davies, Mark. (2008-) Collocates data from The Corpus of
Contemporary American English (COCA). Data available online at https://www.collocates.info. |
|
iWeb |
Davies, Mark. (2018)
The iWeb Corpus. Available online at https://www.english-corpora.org/iWeb/. |
|
COHA |
Davies, Mark. (2010) The Corpus of Historical American English
(COHA). Available online at https://www.english-corpora.org/coha/. |
|
TIME |
Davies, Mark. (2007) TIME Magazine Corpus. Available online at https://www.english-corpora.org/time/. |
|
TV |
Davies, Mark. (2019) The TV Corpus. Available online at https://www.english-corpora.org/tv/. |
|
Movies |
Davies, Mark. (2019) The Movie Corpus. Available online at https://www.english-corpora.org/movies/. |
|
BNC |
Davies, Mark. (2004) British National Corpus (from Oxford University
Press). Available online at https://www.english-corpora.org/bnc/. |
|
NOW |
Davies, Mark.
(2016-) Corpus of News on
the Web (NOW). Available online at https://www.english-corpora.org/now/. |
|
Coronavirus |
Davies, Mark.
(2019-) The Coronavirus Corpus. Available online at https://www.english-corpora.org/corona/. |
|
GloWbE |
Davies, Mark. (2013) Corpus of Global
Web-Based English. Available online at https://www.english-corpora.org/glowbe/. |
|
EEBO |
Davies, Mark. (2017) Early English Books
Online Corpus. Available online at https://www.english-corpora.org/eebo/. |
|
Hansard |
Davies, Mark. (2015) Hansard Corpus.
Available online at https://www.hansard-corpus.org/. |
|
Wikipedia |
Davies, Mark. (2015) The Wikipedia Corpus. Available online at https://www.english-corpora.org/wiki/. |
|
SOAP |
Davies, Mark. (2011-) Corpus of American
Soap Operas. Available online at https://www.english-corpora.org/soap/. |
|
CORE |
Davies, Mark. (2016-) Corpus of Online
Registers of English (CORE). Available online at https://www.english-corpora.org/core/. |
|
Supreme Court |
Davies, Mark. (2017) Corpus of US Supreme Court Opinions. Available
online at https://www.english-corpora.org/scotus/ |
|
CAN / Strathy |
Davies, Mark. (2012-) The Strathy Corpus of Canadian English (from the
Strathy Language Unit, Queen's University).
https://www.english-corpora.org/can/. |
|
Corpus del Español |
Davies, Mark. (2016-) Corpus del Español:
Web/Dialects. Available online at http://www.corpusdelespanol.org/web-dial/.
|
|
Davies, Mark. (2002-) Corpus del Español:
Hiistorical/Genres. Available online at http://www.corpusdelespanol.org/hist-gen/. |
|
Corpus do Português |
Davies, Mark. (2016-) Corpus do Português:
Web/Dialects. Available online at http://www.corpusdoportugues.org/web-dial/. |
|
Davies, Mark and Michael Ferreira. (2006-)
Corpus do Português: Historical Genres. Available online at
http://www.corpusdoportugues.org/hist-gen/. |
|
Google Books |
Davies, Mark. (2011-) Google Books
Corpus.
(Based on Google Books n-grams). Available online at
http://www.english-corpora.org/googlebooks/.
Based on:
Jean-Baptiste Michel*, Yuan Kui Shen, Aviva Presser Aiden, Adrian Veres,
Matthew K. Gray, The Google Books Team, Joseph P. Pickett, Dale Hoiberg,
Dan Clancy, Peter Norvig, Jon Orwant, Steven Pinker, Martin A. Nowak,
and Erez Lieberman Aiden*. Quantitative Analysis of Culture Using
Millions of Digitized Books. Science 331 (2011) [Published online ahead
of print 12/16/2010]. |
|

{kind=link}